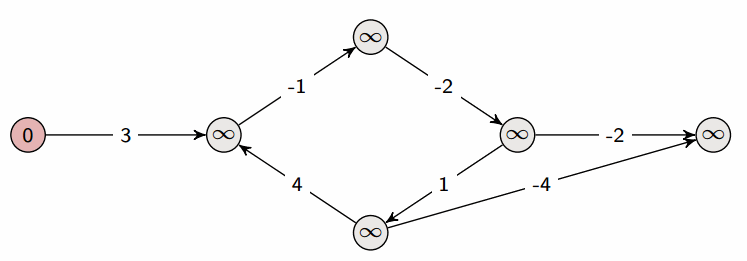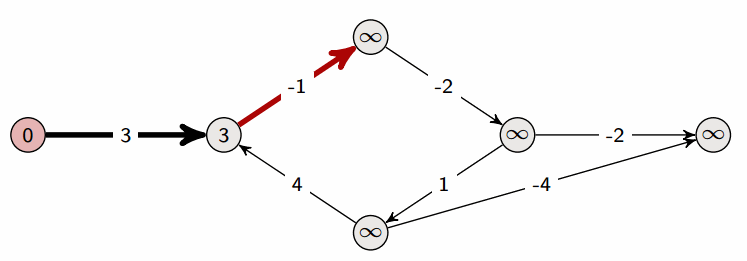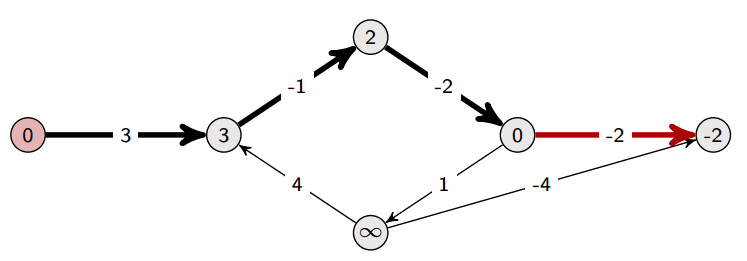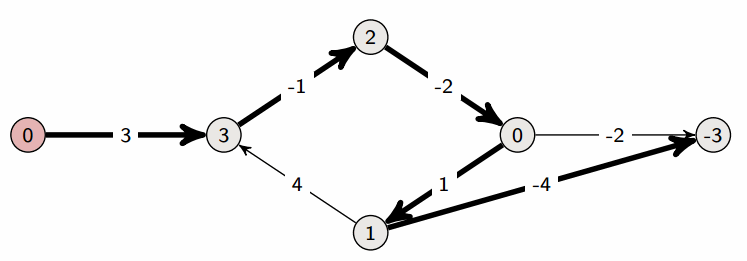
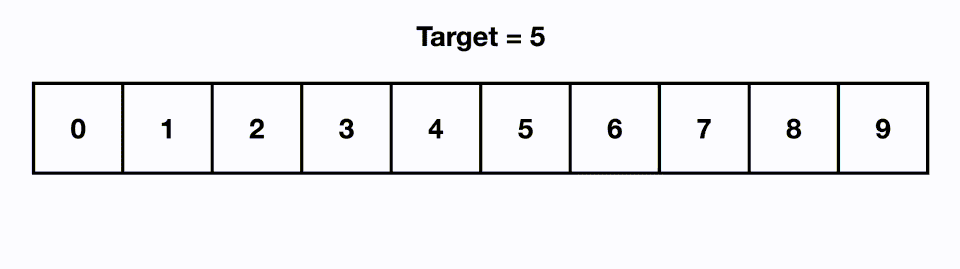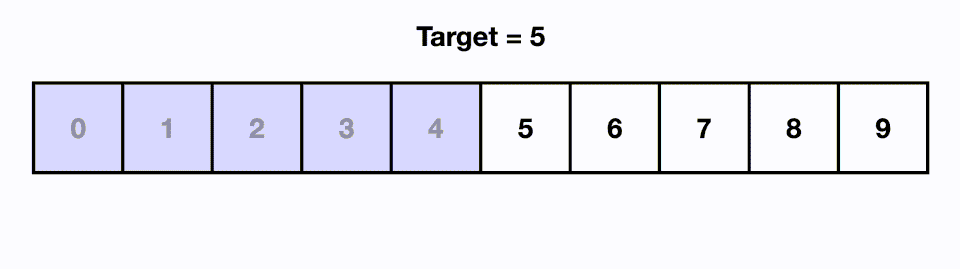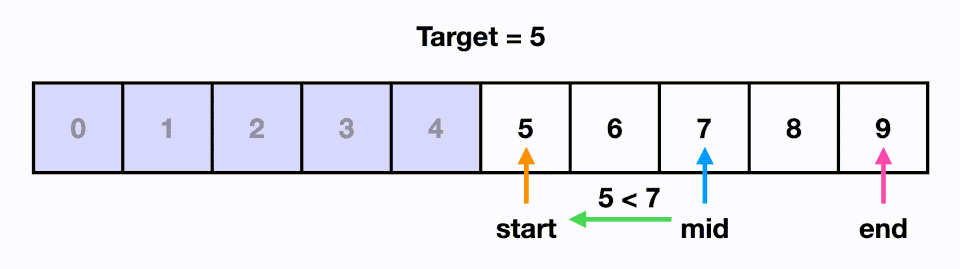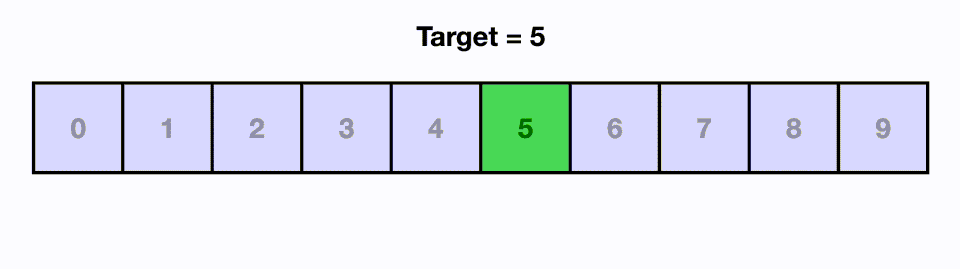
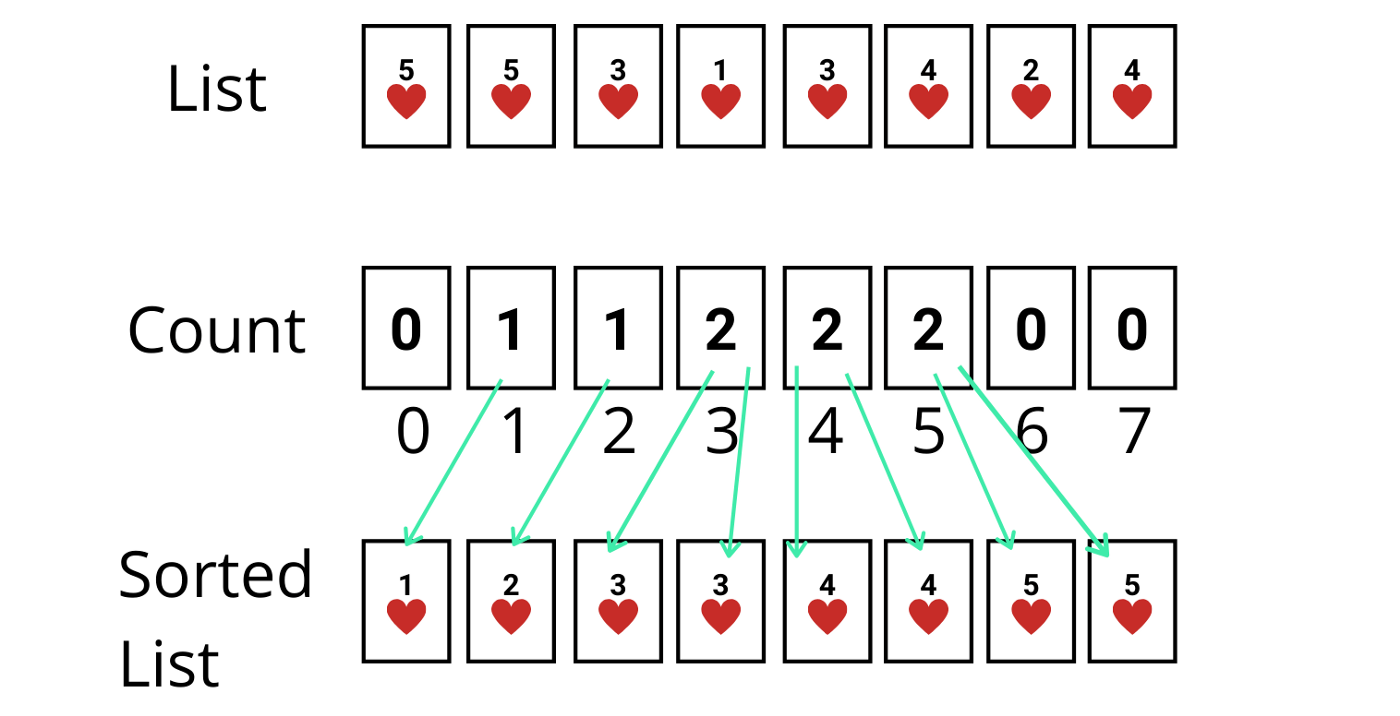
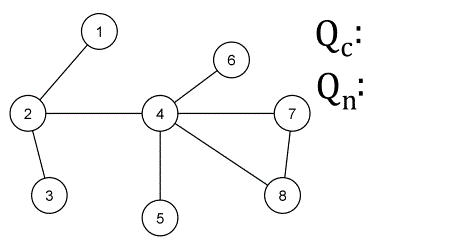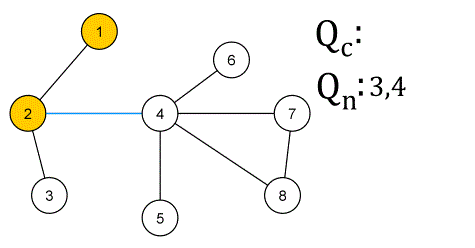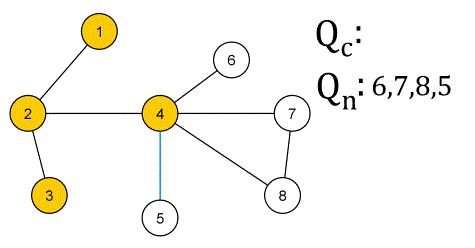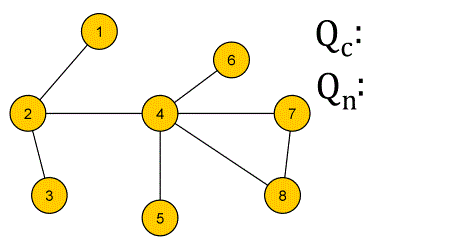
✅ 벨먼-포드 알고리즘 (Bellman-Ford Algorithm) ❕ 기본 개념 - 그래프의 최단 경로 문제를 해결하기 위한 알고리즘 - 최단 경로 문제에서는 간선에 가중치가 부여된 가중 그래프가 주어지며, 시작점부터 종점까지의 경로 중 간선의 가중치 최소합을 구하면 됨 - 가중치가 음수라도 제대로 동작함 - 방향성/비방향성 그래프 모두 적용 가능 - 정점 수를 n, 간선 수를 m이라고 할 때, 가중치 변경 작업을 n회 순회하고, 각 변경 작업에서 각 간선을 1회씩 조사하므로 전체 계산 시간은 O(nm) ❕ 작동 방식 ✔ 구현 방법 (JS) function BellmanFord(graph, V, E, src) { // Initialize distance of all vertices as infinite..