● 목표
- 번호 인식을 위한 전처리로써 자동차 번호판 영상에 대한 이진화 처리
● 세부목표:
- 이 과제에서는 자동차 번호판을 정상의 형태로 변형한 후
- 이진화 하고
- 모폴로지 연산을 이용하여 스무싱 한다.
● 기타:
- 주요한 과정에 대하여 module 함수를 사용해도 무방합니다.
- 필요한 경우 각 단계에서 *적절한* 최적화 가 필요합니다. 여러분의 최적화 노력을 PPT에 간략하게 설명하기 바랍니다.
- 기타 세부적인 사항은 합리적으로 가정하시기 바랍니다.
● 과제의 내용
1. 번호판 영상을 준비한다.
A. 정상이 아닌 비스듬히 촬영한다.
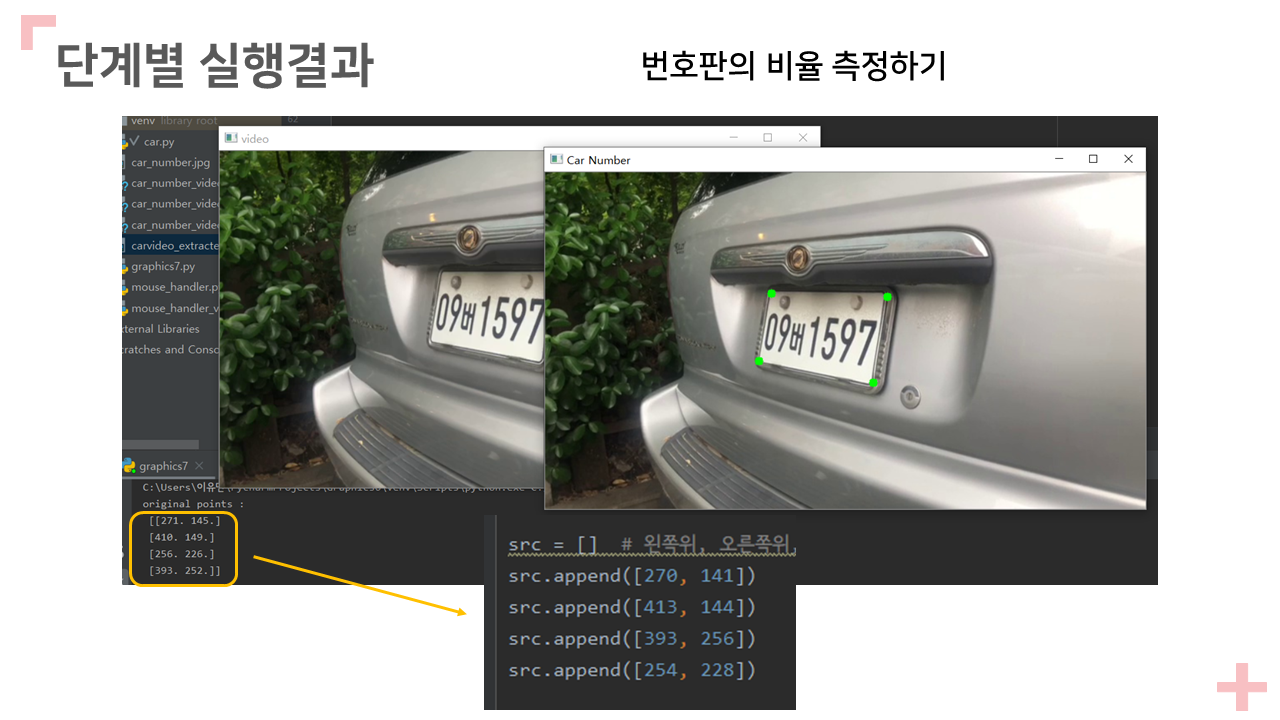
2. 번호판 영상을 정상으로 변환한다.
A. 이전 과제의 코드를 이용하여 투영변환
B. 영상의 크기는 번호판 보다 가로 세로가 10% 더 크게 되도록 조정할 것.
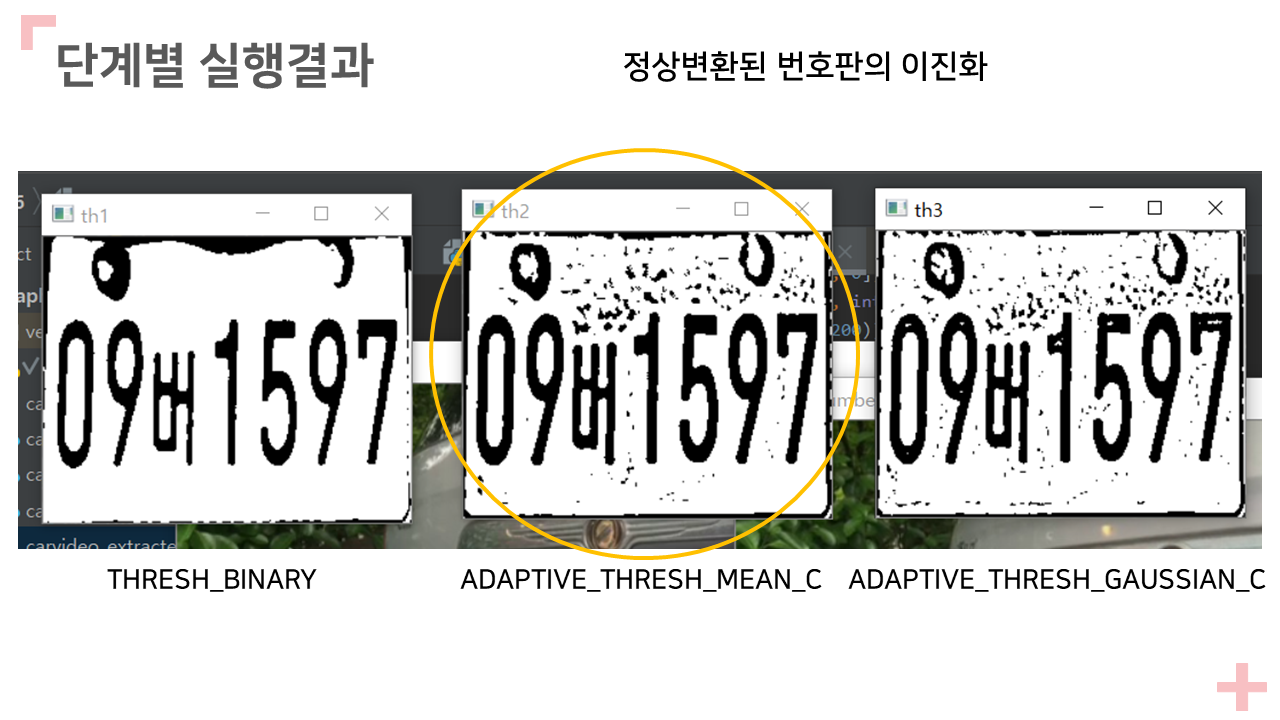
3. 이진화
A. 오츄 또는 adaptive 등 적절한 thresholding 기법 을 사용할 것
B. 파라미터 최적화가 필요함.
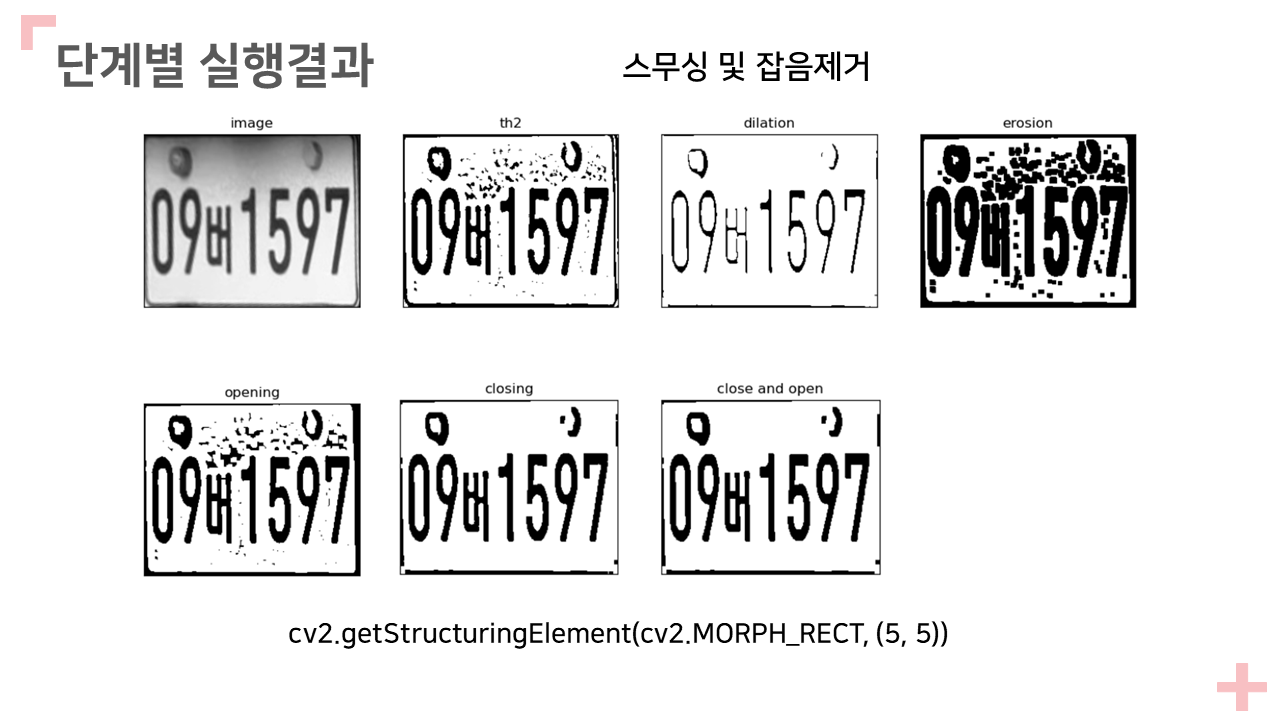
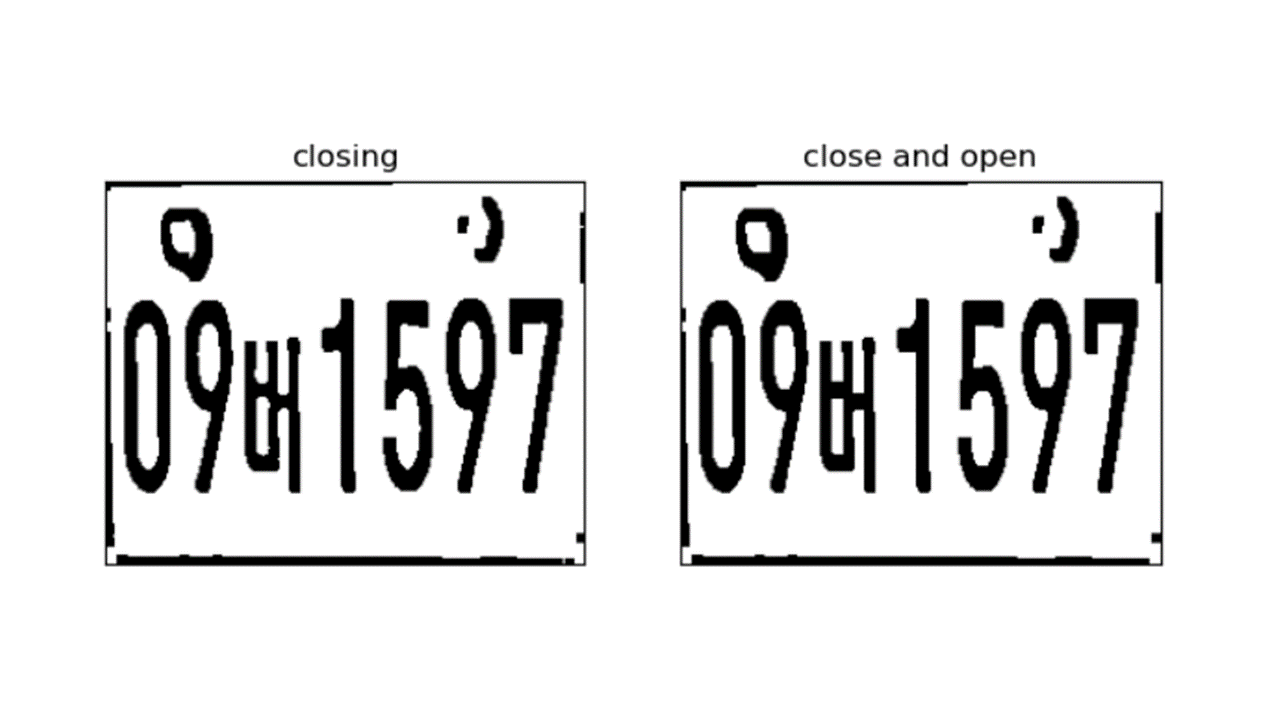
4. 스무싱 및 잡음제거
A. 이진 모폴로지 연산을 이용하여 잡음제거 및 윤곽을 스무싱할 것
B. 적절한 크기와 형태의 SE, 연산의 종류를 선택
5. 다음 단계는 번호 인식임.
A. 전처리는 인식을 위하여 깨끗한 이진 영상을 준비하기 위한 목적임.
B. 번호 인식을 위한 알고리즘을 1가지를 조사하여 별도의 PPT(발표 길이5 -10분, 자동플레이 및 오디오 설명)로 요약하세요.
C. 인식은 프로그램 안해도 됩니다.
6. 각 단계 마다 컬러, 그레이, 이진 영상 등에 적절한 잡음 제거 등의 필터링이 적용되어야 합니다.
과제내용















Code
import cv2
import numpy as np
from matplotlib import pyplot as plt
vid_path = 'car_number_video3.mp4'
cap = cv2.VideoCapture(vid_path)
src = [] # 왼쪽위, 오른쪽위, 오른쪽아래, 왼쪽아래 순으로 각 점의 좌표
src.append([270, 141])
src.append([413, 144])
src.append([393, 256])
src.append([254, 228])
'''
# mouse callback handler
def mouse_handler(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONUP: # 마우스가 좌클릭을 했을때 (4번의 클릭으로 좌표 얻기)
img = cv2.imread('carvideo_extracted.jpg')
src.append([x, y])
for xx, yy in src: # 클릭한 곳에 점 그리기
cv2.circle(img, center=(xx, yy), radius=5, color=(0, 255, 0), thickness=-1)
cv2.imshow('Car Number', img)
# perspective transform
if len(src) == 4:
src_np = np.array(src, dtype=np.float32)
print("original points : \n", src_np)
'''
pos_frame = cap.get(cv2.CAP_PROP_POS_FRAMES)
frame_count = 0
while True:
flag, frame = cap.read()
frame_count += 1
if flag:
# frame을 읽을 준비가 완료되었을 때, 그 해당 frame을 pos_frame에 저장
cv2.imshow('video', frame)
pos_frame = cap.get(cv2.CAP_PROP_POS_FRAMES)
'''
else:
# frame 이 준비되지 않았다면 다시 읽기를 시도해본다
cap.set(cv2.CAP_PROP_POS_FRAMES, pos_frame-1)
# 다음 frame이 준비될 때까지 기다리기
cv2.waitKey(1000)
'''
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT):
# 현재까지 읽은 frame 의 수가 전체 frame 수와 같아진다면 읽기를 중단, 다시 처음으로 돌아감. (반복재생)
cap.open(vid_path)
if frame_count == 10:
# 10번 frame을 이미지 파일로 저장해서 나머지 과정들 처리.
cv2.imwrite('carvideo_extracted.jpg', frame)
#cv2.namedWindow('Car Number')
#cv2.setMouseCallback('Car Number', mouse_handler) # 마우스 이벤트 전달
#cv2.imshow('Car Number', frame)
if cv2.waitKey(1) == 32:
break
cap.release()
#cv2.destroyAllWindows()
ext_img = cv2.imread('carvideo_extracted.jpg')
# 32비트로 바꿔줌
src_np = np.array(src, dtype=np.float32)
# width, height 길이 계산
width = max(np.linalg.norm(src_np[0] - src_np[1]), np.linalg.norm(src_np[2] - src_np[3]))
height = max(np.linalg.norm(src_np[0] - src_np[3]), np.linalg.norm(src_np[1] - src_np[2]))
# width, height 비율
width_ratio = (width / height)
height_ratio = 1
# 2배 더 크도록 픽셀 크기 맞춤
dst_np = np.array([[0, 0],
[int(width_ratio * 200), 0],
[int(width_ratio * 200), int(height_ratio * 200)],
[0, int(height_ratio * 200)]
], dtype=np.float32)
M = cv2.getPerspectiveTransform(src=src_np, dst=dst_np)
result = cv2.warpPerspective(ext_img, M=M, dsize=(int(width_ratio * 200), height_ratio * 200))
cv2.imshow('Car Number', result)
cv2.waitKey(0)
result_grey = cv2.cvtColor(result, cv2.COLOR_BGR2GRAY)
#ret, th1 = cv2.threshold(result_grey, 127, 255, cv2.THRESH_BINARY)
th2 = cv2.adaptiveThreshold(result_grey, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 15, 2)
#th3 = cv2.adaptiveThreshold(result_grey, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 15, 2)
#cv2.imshow('th1', th1)
#cv2.imshow('th2', th2)
#cv2.imshow('th3', th3)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
dilation = cv2.dilate(th2, kernel, iterations=1)
erosion = cv2.erode(th2, kernel, iterations=1)
opening = cv2.morphologyEx(th2, cv2.MORPH_OPEN, kernel)
closing = cv2.morphologyEx(th2, cv2.MORPH_CLOSE, kernel)
closenopen = cv2.morphologyEx(closing, cv2.MORPH_OPEN, kernel)
#titles = ['image', 'th2', 'dilation', 'erosion', 'opening', 'closing', 'close and open']
#images = [result_grey, th2, dilation, erosion, opening, closing, closenopen]
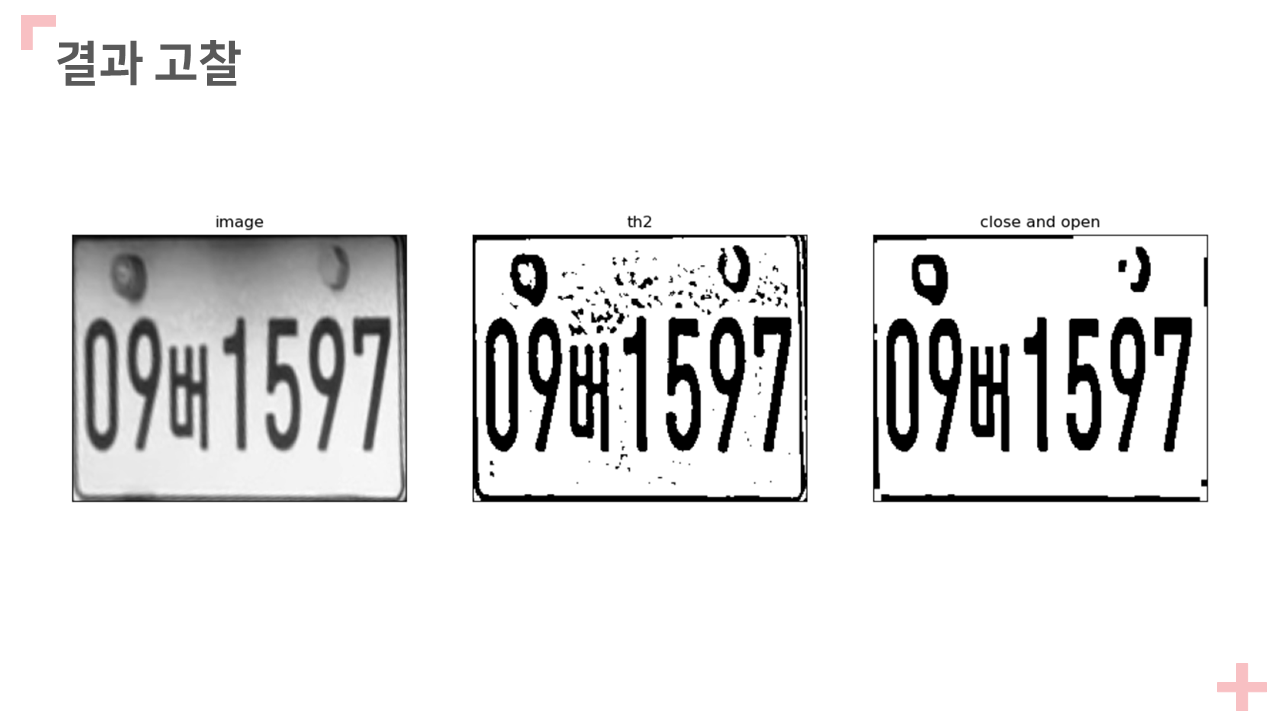
titles = ['image', 'th2', 'close and open']
images = [result_grey, th2, closenopen]
for i in range(3):
plt.subplot(1, 3, i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
if cv2.waitKey(0) == 32:
cv2.destroyAllWindows()
점수 10/10
❤와 댓글은 큰 힘이 됩니다. 감사합니다 :-)
'archive. > Schoolwork' 카테고리의 다른 글
| [Java] 데이터베이스기초 과제 - JDBC 직원 정보 검색 시스템 Company GUI (1) | 2021.03.03 |
|---|---|
| [Python] 그래픽스 09주차 과제 - 영역 검출을 위한 영상 전처리 (명함 인식) (5) | 2020.09.05 |
| [Python] 그래픽스 06주차 과제 - Perspective transform (0) | 2020.09.05 |
| [Python] 그래픽스 05주차 과제 - Canny Edge 검출 (9) | 2020.09.05 |
| [Python] 그래픽스 04주차 과제 - 웹캠영상에서 얼굴 검출 (0) | 2020.09.05 |